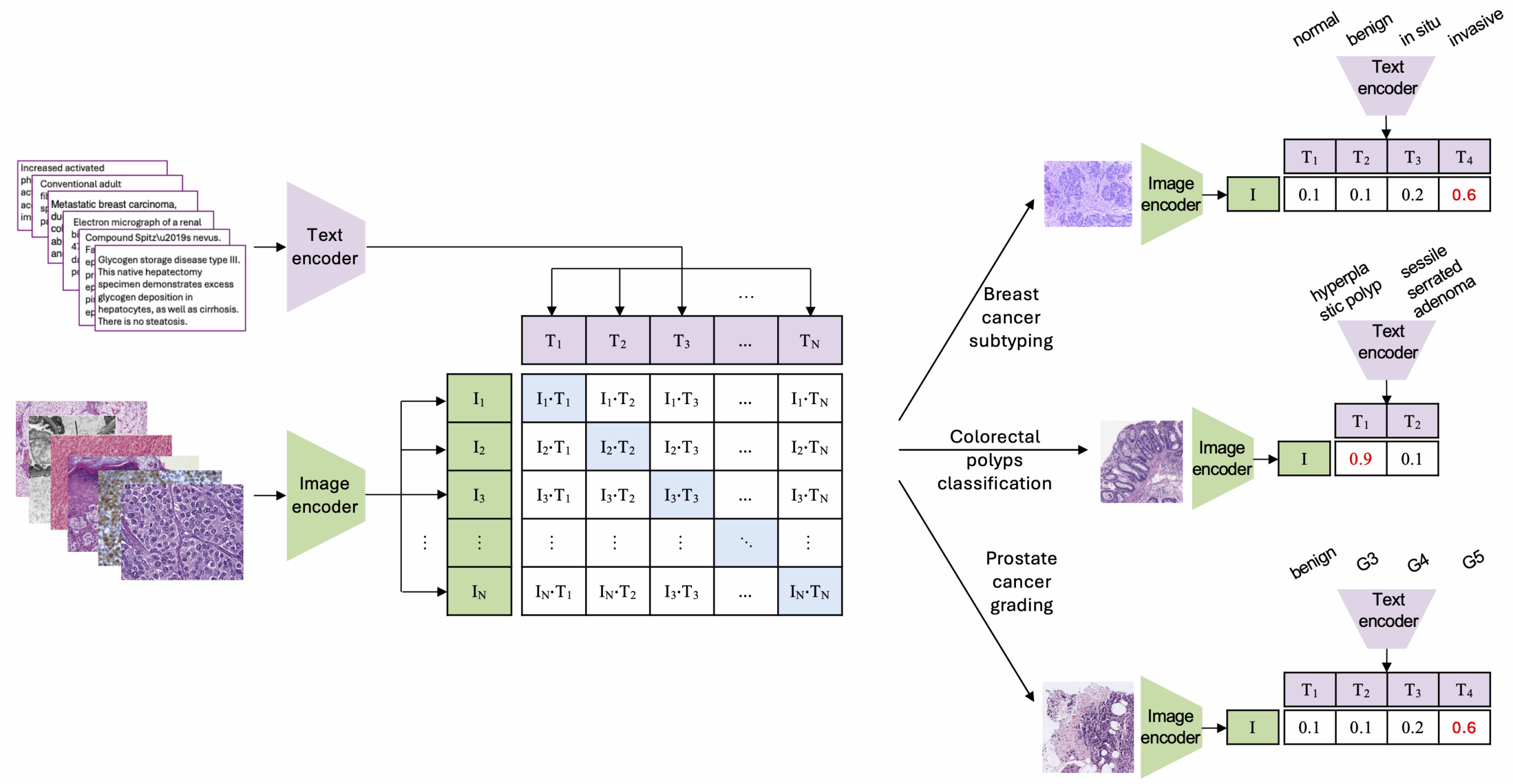
Vision-Language Models (VLMs) are trained with images in conjunction with text descriptions, which helps them capture complex visual signal. By learning from large datasets with millions of image–text pairs, these models can perform zero-shot classification—recognizing new patterns without specific training for each task. Their success with natural images has led to their use in histopathology, with specialized VLMs such as CONCH and QuiltNet.
However, there is a challenge: when trained on broad datasets, these models may perform less well on specialized medical tasks. The usual solution is supervised fine-tuning with carefully labeled examples. However, creating these labels takes valuable pathologist time.
Our research solves this problem without adding work for pathologists. We extract domain- and task-relevant image-caption pairs from existing resources, such as the Quilt1M histopathology image-caption database. For example, in breast cancer classification, domain-relevant pairs include captions with the word “breast,” while task-relevant pairs are a subset that contain specific class names such as “normal,” “benign,” “in situ,” and “invasive.” We then use these pairs to continue pretraining the VLM— a process we call Domain-adaptive PreTraining (DAPT) and Task-adaptive PreTraining (TAPT). This lets the models focus on the features that matter for new tasks without any human annotations.

We tested this approach on two histopathology VLMs across three real pathology challenges, breast cancer subtyping, colorectal polyp classification, and prostate cancer grading, and found that it greatly improves zero-shot performance comparing to the original unadapted VLM.
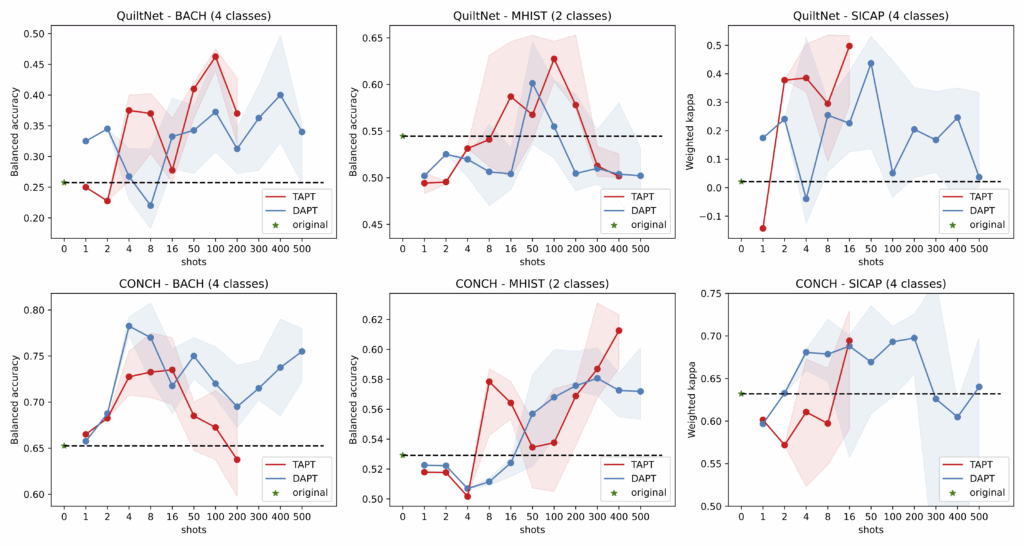
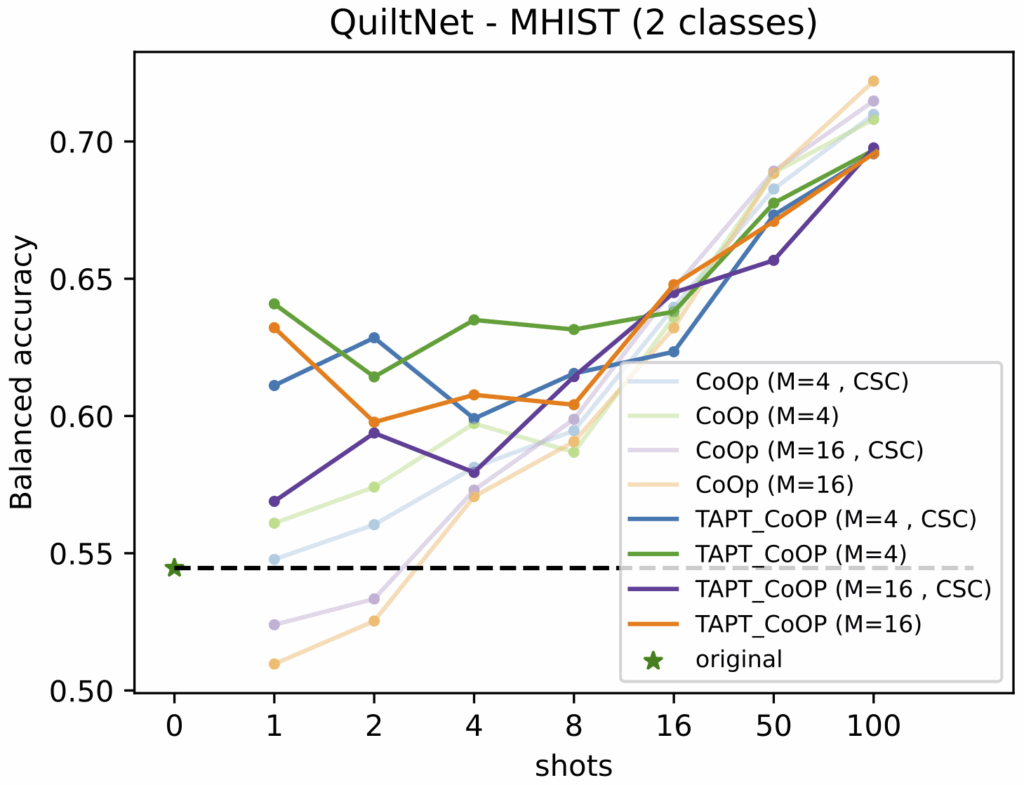
The performance of leading few-shot learning method CoOp is also improved when applied to the adapted model, especially for small few-shot sets.
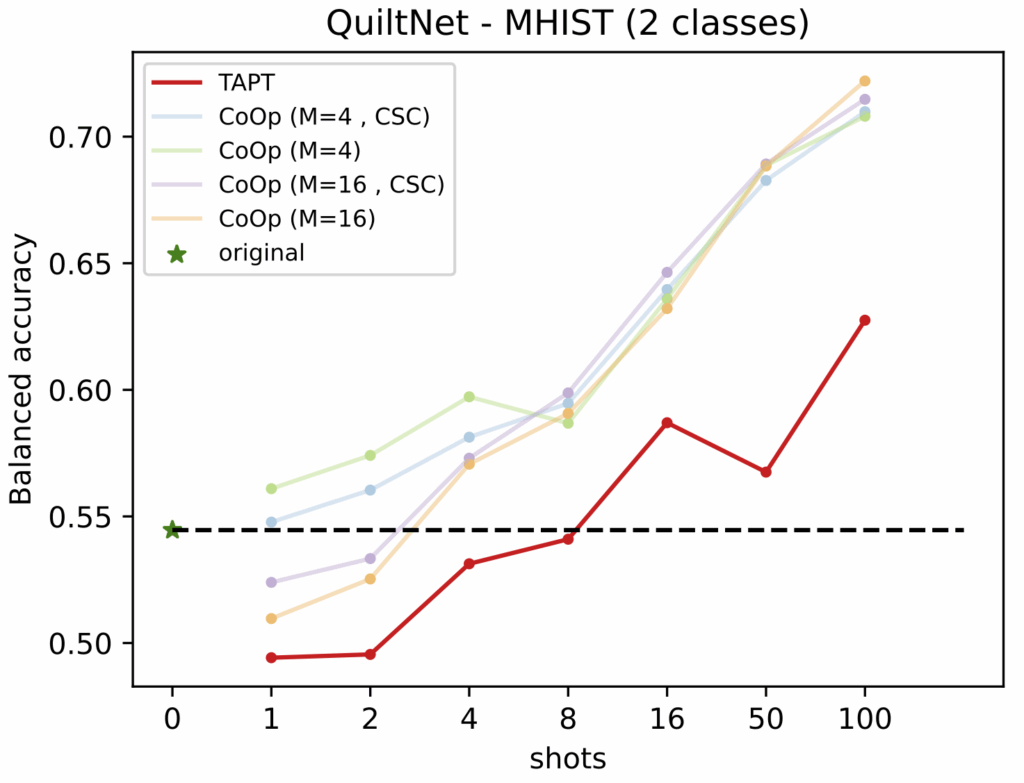
Continued pretraining can even match the performance of few-shot method CoOp with more training data, but all without any labels.
The effectiveness of our method, together with its task-agnostic design, and annotation-free workflow make it a promising pathway for adapting VLMs to new histopathology tasks.
The paper was selected as a talk on this year’s COMPAYL MICCAI workshop.




Comments are closed